
- Today
- Total
개발하는 고라니
Redis Keyspace Notification 과 지연 이벤트 본문
일전에 지연 이벤트를 구현하기 위해 batch를 이용한 polling 방식과 Rabbit MQ, 그리고 redis의 keyspace notification 을 알아보았습니다.
그중 제가 채택한 redis를 이용해서 어떻게 구현했고, 아쉬웠던 점과 놓쳤던 부분에 대해 버그가 발생했던 부분을 회고할 겸 글을 작성합니다.
Architecture
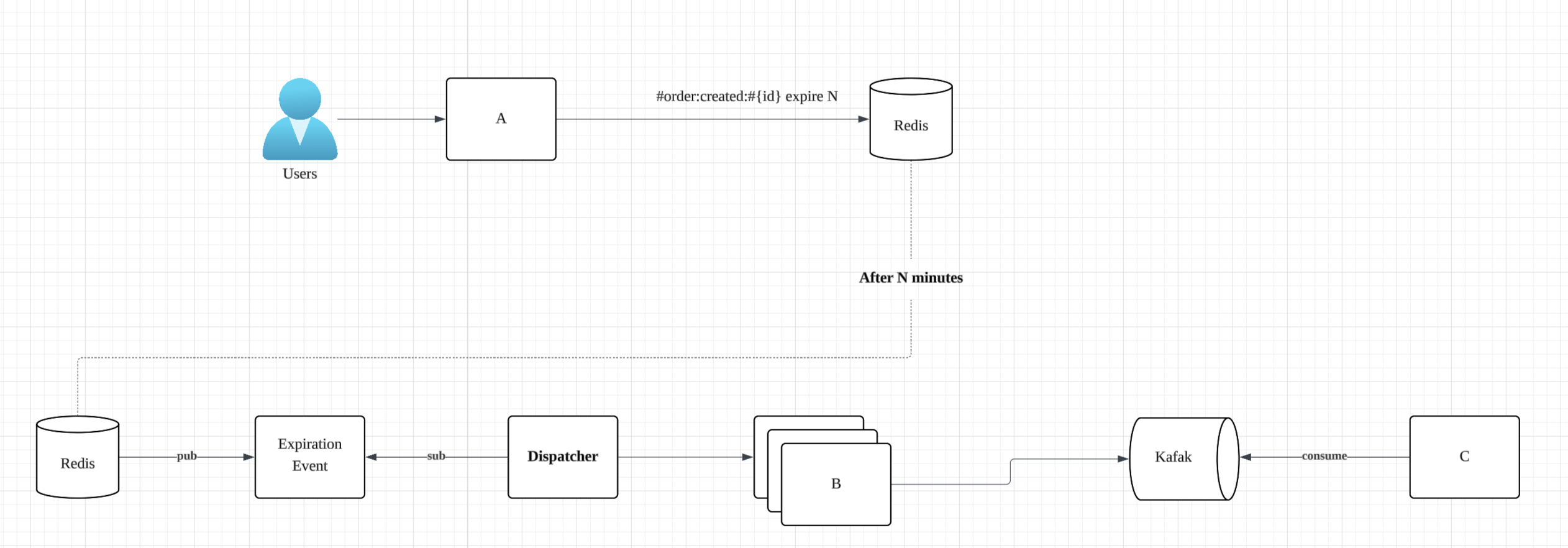
처음 완성시킨 아키텍처에서 일부분을 도식화 하면 아래와 같습니다.

- A 에서 주문 등록 처리 후 Redis에 N분의 TTL과 함께 Key:Value를 등록
- N분 후 Key가 만료됨에 따라 Redis에서 Event를 발행
- 각 B 서버(복수)에서 동일한 Event 수신
- Redis 분산락 획득 시도
- 락을 획득한 서버만 주문이 결제가 되었는지 확인 후 안되었으면 주문 취소, 락을 획득하지 못한 서버는 아무 행동하지 않음
- 주문 취소 되었으면 Kafka에 주문 취소 Event 발행
- C 서버에서 Kafka Event를 받아 후속 로직 처리 (예: 알림톡 발송 등)
네, 다소 복잡한 구조를 띈다고 생각할 수 있습니다.
분산락이 필요했나?
라는 질문을 던질 수 있을 것 같습니다.
현 구조에서는 필요했습니다.
redis keyspace notification은 기본적으로 pub/sub 으로 동작합니다.
pub/sub은 메세지 큐 방식(point-to-point)과 다르게 "Broadcast" 방식을 사용합니다. 즉, 모든 Subscriber 에게 동일한 메세지를 전달합니다.
위의 그림에서 B는 단일 인스턴스가 아닌 다중 인스턴스로 구성되어있습니다. B가 5개라면 5개의 서버 모두 하나의 동일한 메세지(이벤트)를 받습니다.
우리는 Race Condition을 생각해야 합니다. 중복으로 처리가 되어선 안되기 때문입니다.
그래서 Redlock을 획득한 한 대의 서버만 이벤트를 받았다고 판단하고 후속 조치를 할 수 있도록 했습니다.
다른 방법은 없었을까?
더 간단한 방법도 존재합니다. 위 아키텍처에서 Dispatcher 서버를 추가하는 것 입니다.
단일 인스턴스로 구성된 Dispatcher 서버를 추가하면 Race Condition에 대한 걱정을 없앨 수 있고, 아키텍쳐 또한 단순해집니다.
다만, 단일 인스턴스의 취약점을 고려해야합니다.
"고가용성(High Availablity)" 과 "SPOF(Single Point of Failure)"
단일 인스턴스로 구성했기 때문에 고가용성은 당연히 어려우며, SPOF 가 가장 두드러지게 나타납니다.
Dispatcher 서버가 죽었거나 배포로 인한 Down Time이 발생하면, 치명적인 장애로 이어집니다.
redis pub/sub은 "Fire and Forget" 방식을 채택하고 있으므로 발행 후 수신하지 못한 이벤트는 유실됩니다.
따라서 Dispatcher 서버를 두어도 이중화에 대한 방안도 마련해야합니다.
아마 Active-Active 또는 Standby-Active 서버 구성을 고려해볼 수 있겠습니다.
다만, Active-Active 는 주로 분산락을 이용하니 기존 구성과 다를게 없습니다.
Standby-Active는 하나의 리더를 두고 만약을 대비해 Failover가 가능한 서버를 준비해두는 것입니다.
즉, 처음 구조처럼 고려한 이유는 현재로서 Dispatcher 서버를 구성하고 별도로 두는 것이 오버 엔지니어링이라 판단했기에 Service Application 서버에서 레디스 이벤트를 수신하도록 했습니다.
아쉬웠던 점
은총알은 없다는 말을 아시나요?
분산락을 이용하면 race condition에서 중복처리가 발생하지 않으리라 확신했습니다.
하지만 발생하더군요... 다행히 치명적인 장애로 이어지진 않았지만, 결국 알림톡을 중복으로 수신한 고객이 발생했습니다.
버그 발생의 원인은 다음과 같이 복합적인 이유로 판단했습니다.
1. B에서 redis event 수신하는 시점이 100% 동일하지 않음
2. 분산락 획득 후 반납하기 까지 너무 빨랐음
3. 분산락 획득까지 대기 시간이 너무 길었음
3대의 B 서버가 있다는 가정하의 한 케이스를 제시해보겠습니다.
- 00:00:00 - Redis Event 발행됨
- 00:00:01 1ms - B1 서버가 Event를 수신, 분산락 획득 시도
- 00:00:01 1ms - B2 서버가 Event를 수신, 분산락 획득 시도
- 00:00:01 2ms - B1 서버 분산락 획득
- 00:00:01 20ms - B2 서버 분산락 획득 포기 후 종료
- 00:00:01 30ms - B3 서버가 Event를 수신, 분산락 획득 시도
- 00:00:01 50ms - B1 서버 로직 처리 후 분산락 반납
- 00:00:01 50ms - B3 서버가 분산락 획득
- 00:00:01 90ms - B3 서버 로직 처리 후 분산락 반납
전부 위와 같은 케이스는 아닐테지만, 어쨋든 의도치 않게 버그가 발생했습니다.
이에 저는 응급 처치로 B에서 분산락을 획득 했더라도 후속 로직을 처리하기 전 Redis에 특정 Key를 넣어 또 다시 중복처리를 방지하게 되었습니다.

'Restart' 카테고리의 다른 글
| Redis Keyspace Notification playground (0) | 2025.10.12 |
|---|---|
| Delayed Event(지연 이벤트) (3) | 2025.10.12 |

