
- Today
- Total
개발하는 고라니
[JPA] JPA란? 본문
JPA (Java Persistence API)
Java 진영의 ORM 기술 표준이다.
- 과거 EJB라는 자바진영의 ORM을 구현한 것이 있었는데, 이를 좀더 개선하고자 오픈소스로 만들어진 것 중 하나가 'hibernate'이다.
- 이에 자바진영에서 hibernate를 만든사람을 데려와 다듬고 표준 스펙으로 만든 것이 JPA이다.
- JPA는 인터페이스의 집합이며, 실제로 내부를 보면 동작하는 것이 아니다.
- JPA 2.1를 구현한 여러 구현체 중 3가지를 뽑자면,
Hibernate, EclipseLink, DataNucleus 가 존재한다.
Q.
- ORM을 구현한 오픈소스가 hibernate이고,
자바 진영에서 hibernate를 다듬어 표준스펙으로 만든 것이 JPA라고 말씀하셨는데요.
바로 뒤에서 JPA 2.1 표준 명세를 구현한 3가지 구현체에 hibernate가 있는 것을 확인하였습니다.
여기서 드는 의문점은, 그럼 hibernate는 다시 JPA 2.1을 구현을 한 것인지 궁금합니다.
A. 답변
- JPA는 Application과 JDBC API 사이에서 동작한다.

개발자가 직접 JDBC API를 사용하는 것이 아닌(SQL을 직접 작성하는 것이 아닌)
JPA에 명령하면 알아서 JDBC API를 사용해 SQL을 만들어 호출 및 DB에 날리고 결과를 받아 전달한다.
패러다임의 불일치
1. JPA와 상속
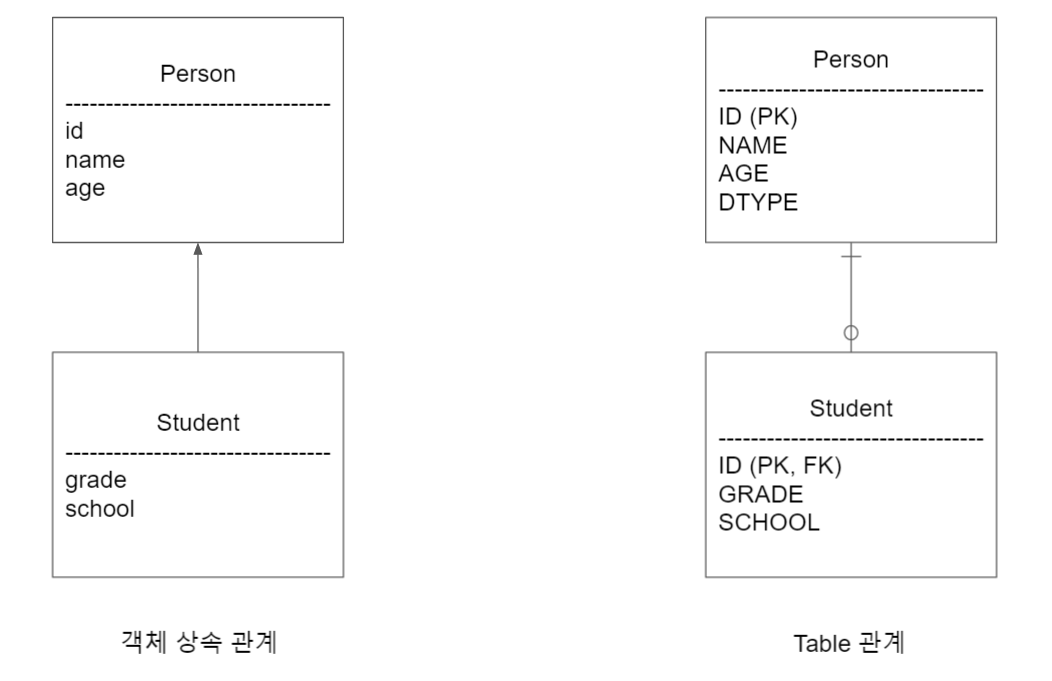
- 객체에서의 상속과 관계형 데이터베이스에서의 상속은 다르다. (사실 데이터베이스에서 상속과 유사한 것은 있으나, 상속이라는 개념은 없다.)
- 예를 들어, 저장하는 과정을 생각해보자, JPA를 사용하지 않는다면, Person 테이블과 Student 테이블에 각각 INSERT를 날려줘야 한다.
하지만 JPA를 쓴다면, entityManager.persist(student) 한 줄이면 된다. (실제로 INSERT쿼리가 2개로 나뉘어 들어간다)
- 조회의 경우도 마찬가지이다. Student를 조회하기 위해 JOIN은 불가피하다. 하지만 JPA에서는 entityManager.findById(id) 같은 메서드를 사용하면 알아서 가져다 준다.
2. JPA와 연관관계
class Person{
String name;
int age;
School school
}
class School{
String name;
}
...
person.setSchool(school);
entityManager.persist(person);- JDBC API를 이용해 Java에서 처럼 person에 school을 set해주고 person을 저장하면 알아서 될까? 그렇지 않다.
person의 INSERT 따로, school의 INSERT 따로 처리해줘야 한다.
JPA를 사용한다면 한줄이면 알아서 2개의 INSERT 쿼리가 날아간다.
3. 신뢰할 수 있는 엔티티, 계층 및 객체 그래프 탐색
- 일반적으로 MyBatis나 JDBC Template, JDBC API를 사용해서 Member를 가져오면, Member가 참조하는 테이블의 데이터를 모두 가져올 수 있는가?
답은 "있다"이다. 하지만 그것은 그렇게 Query를 작성했을 때의 얘기이다. 즉 개발자가 그렇게 의도를 해야 데이터를 가져올 수 있다는 것이다.
하지만 JPA는 EAGER든 LAZY든 어떤 strategy를 사용해서 Member가 참조하는 다른 테이블의 데이터들을 가져올 수 있다. 따라서 신뢰할 수 있는 엔티티가, 계층이 되는 것이다.
4. JPA와 비교
- 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장한다. 동일한 객체라는 것이다.
- List<Member>를 예를 들어보자,
Member member1 = list.get(0);
Member member2 = list.get(0);member1 == member2 이다. JPA도 마찬가지로 "동일한 트랜잭션"내에서 조회한 엔티티는 동일함을 보장한다.
JPA 성능 최적화 기능
- 1차 캐시(cache)와 동일성 보장
- 트랜잭션을 지원하는 쓰기지연
- 지연 로딩
- JPA는 어플리케이션과 JDBC API 사이에서 동작하는 것 이라고 하였다. 계층 사이에 중간 계층이 있으면, 모아서 보내는 '버퍼링'을 할 수 있고, 읽을 때 '캐싱'을 할 수 있다.
다음은 인프런 질문 남겨주신 분의 캐시에 대한 답변 중 일부를 발췌한 것이다.
JPA는 1차 캐시, 2차 캐시라는 것을 제공합니다.
1차 캐시
먼저 JPA의 1차 캐시는 쉽게 이야기해서 1명의 고객의 요청이 들어오고 나갈 때 까지 유지되는 생존 범위가 매우 짧은 캐시입니다. 이것은 애플리케이션 서버 메모리에 저장됩니다. (더 정확히는 애플리케이션에서 데이터베이스 트랜잭션을 시작하고 종료할 때 까지 유지되는 캐시)
이런 1차 캐시는 사실 일부 성능 향상이 있기는 하지만, 사용 목적이 성능 향상 때문에 사용하는 것은 아니고, JPA의 내부 매커니즘을 유지하기 위해 사용됩니다. 그리고 여러명이 동시에 같은 캐시에 접근할 수 없습니다.
2차 캐시
본격적인 캐시는 여러 사용자가 동시에 같은 데이터를 요청하면 애플리케이션 메모리나 캐시 별도의 캐시 서버에 저장되어있는 데이터를 조회하는 것이 빠르겠지요. JPA는 엔티티 단위로 공유 가능한 캐시를 제공하는데 이를 2차 캐시라 합니다. 그런데 이런 2차 캐시는 너무 복잡하고, 다루기 쉽지 않아서, 실무에서는 애플리케이션 레벨의 캐시를 더 많이 사용합니다.
애플리케이션 레벨 캐시
JPA를 사용하더라도, JPA가 제공하는 캐시가 아니라, 말씀하셨던 마이바티스 같은 구조를 사용할 떄와 동일한 캐시 구조도 사용할 수 있습니다.
출처: https://www.inflearn.com/questions/71552
JPA 구동 방식
- Persistence라는 클래스가 META-INF/persistence.xml을 조회해
- EntityManagerFactory를 생성하고
- 필요할 때 마다(고객의 요청이 있을 때 마다) EntityManager를 생성해 사용한다
(사용하고 버린다)
※ EntityManagerFactory는 DB당 하나만 생성, 어플리케이션 전체에서 공유한다.
※ EntityManger는 쓰레드 간 공유를 해선 안되고, 사용하고 버려야 한다.
※ JPA의 모든 데이터 변경은 Transaction 안에서 일어나야한다. (조회는 예외)
# Reference / 출처
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 | 강의
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다., 본 강의는 자바 백엔
www.inflearn.com
김영한님의 자바 ORM 표준 JPA 프로그래밍 - 기본편 중 (JPA 소개)
'Framework > JPA (Hibernate)' 카테고리의 다른 글
| [JPA] 벌크 연산 (Bulk Operation) (0) | 2021.08.05 |
|---|---|
| [JPA] 페치 조인 (FETCH JOIN) (0) | 2021.08.05 |
| [JPA] Cascade / OrphanRemoval (0) | 2021.07.25 |
| [JPA] Proxy (0) | 2021.07.23 |
| [JPA] 상속관계 매핑 (0) | 2021.07.23 |



