
- Today
- Total
개발하는 고라니
[Spring Boot] Spring Data JPA - JPA 본문
# ORM과 JPA
- JPA(Java Persistence API)
- Java Persistence API의 약자로 Java 언어를 통해 DB와 같은 영속 계층을 처리하고자 하는 스펙이다.
- JPA를 이해하기 위해 ORM(Object Relational Mapping)이라는 기술을 선행해야 한다.
- ORM을 Java 언어에 맞게 사용하는 '스펙'이다. 따라서 ORM이 조금 더 상위 스펙이되고, JPA는 Java 언어에 국한된 개념이라고 볼 수 있다.
- JPA는 단순한 스펙이기 때문에 해당 스펙을 구현하는 구현체마다 회사의 이름이나 프레임워크의 이름이 다르게 된다. 다양한 프레임워크가 있지만 가장 유명한 것은 'Hibernate'이다.
- 기존 EJB에서 제공되던 Entity Bean을 대체하는 기술이다.
- ORM이기 때문에 자바 클래스와 DB Table을 매핑한다. (SQL을 매핑하지 않는다.)
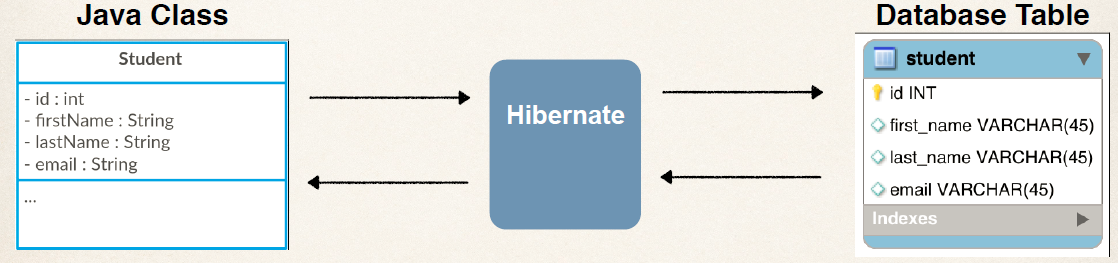
- ORM(Object Relational Mapping)
- ORM은 객체지향과 관련이 있다. '객체지향 패러다임을 관계형 데이터베이스에 보존하는 기술'이라고 할 수 있다.
- 패러다임 입장에서 보면 '객체지향 패러다임을 관계형 패러다임으로 매핑(Mapping)해 주는 개념'
- ORM의 시작은 '객체지향'의 구조가 '관계형 데이터베이스'와 유사하다는 점에서 시작한다. 객체지향 언어 중 '클래스'를 사용하는 언어는 특히 그러한 경우인데 예를 들어 '클래스' 장치를 사용하는 OOP 프로그래밍 언어들은 어떠한 데이터의 구조를 잡기 위해 우선적으로 클래스를 설계한다.
- 관계형 데이터베이스를 다루는 입장에서는 클래스는 아니나 '테이블'을 설계한다. 새로운 테이블에는 컬럼을 정의하고 컬럼에 맞는 데이터 타입을 지정해서 데이터를 보관하는 틀을 만든다는 의미에서 클래스와 상당히 유사하다.
- ORM은 자바 객체를 DB 테이블로 매핑함으로써 객체간 관계를 바탕으로 SQL을 자동으로 생성하지만, Mapper는 SQL을 명시해주어야 한다.
- 클래스와 테이블이 유사하듯 '인스턴스'와 'Row(레코드 또는 튜플)'도 상당히 유사하다. 객체지향에서는 클래스에서 인스턴스를 생성해 인스턴스라는 '공간'에 데이터를 보관하는데, 테이블에서는 하나의 'Row'에 데이터를 저장하게 된다. 여기서의 유일한 차이는 '객체'라는 단어가 '데이터 + 행위(메서드)'라는 의미라면 'Row'는 '데이터'만을 의미한다는 점이 다를 뿐이다. (데이터베이스에서는 '개체(Entity)'라는 용어를 사용한다.)
- 이와 같이 객체지향과 관계형 데이터베이스(RDBMS)는 유사한 특징을 갖는다. 이런 특징에 기초해 '객체지향을 자동으로 관계형 데이터베이스에 맞게' 처리해주는 기법에 대해 아이디어를 내기 시작했고 그것이 ORM의 시작이다.
# Spring Data JPA 그리고 JPA
- Spring Boot는 JPA의 구현체 중 'Hibernate'라는 구현체를 이용한다. 이는 Open Source로 ORM을 지원하는 프레임워크이다.
- "Spring Data JPA"는 Hibernate를 스프링 부트에서 쉽게 사용할 수 있는 추가적인 API들을 제공한다.
- 다른 프레임워크도 그러하듯 Hibernate도 독립된 프레임워크이다. 따라서 스프링 부트가 아닌 스프링에서도 Hibernate와 연동하여 사용이 가능하다.)
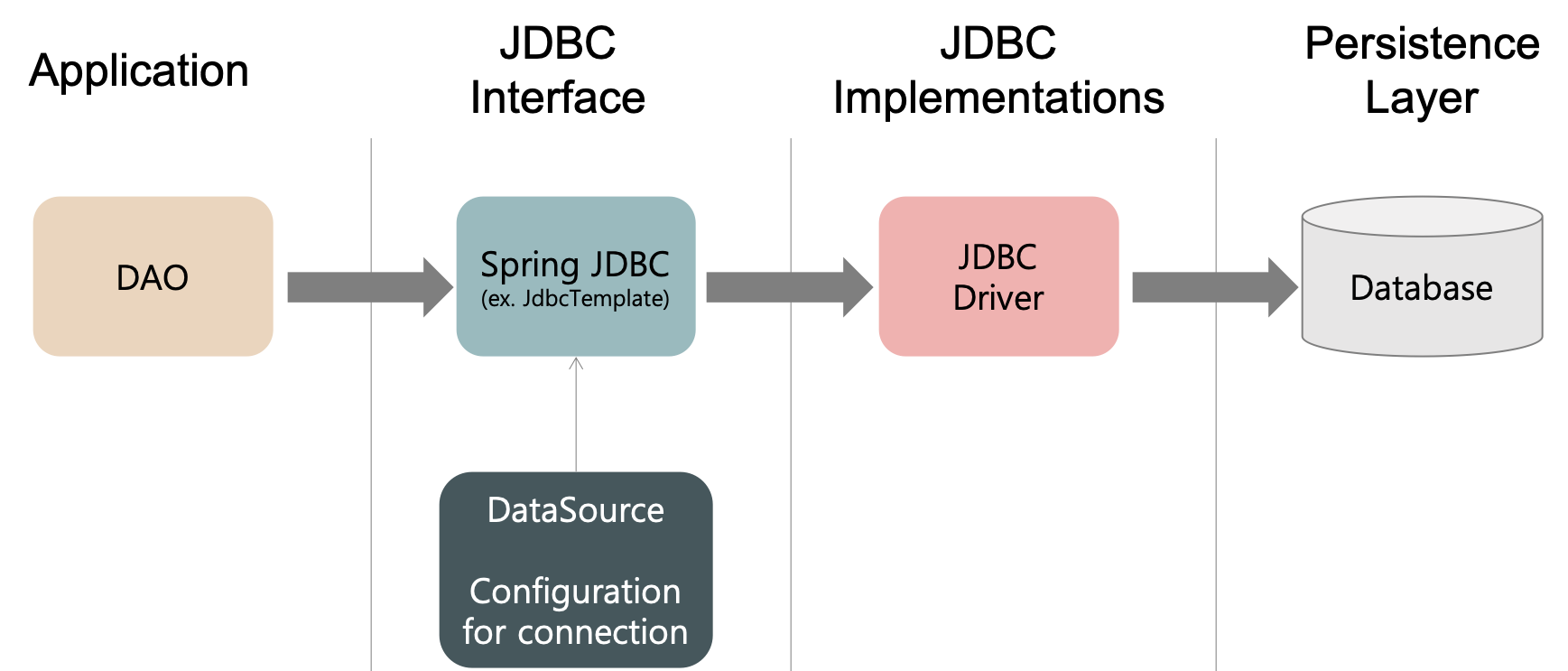
- JPA는 Application과 JDBC사이에서 동작한다.
- 개발자가 JPA를 사용하면, JPA 내부에서 JDBC API를 사용해 SQL을 호출하여 DB와 통신한다.
# 엔티티 클래스와 JpaRepository
* Spring Data JPA가 개발에 필요한 것은 단 두 종류의 코드만으로 가능하다.
- JPA를 통해 관리하게 되는 객체(엔티티 객체(Entity Object))를 위한 엔티티 클래스
- 엔티티 객체들을 처리하는 기능을 가진 Repository
* Repository는 Spring Data JPA에서 제공하는 인터페이스로 설계하는데 스프링 내부에서 자동으로 객체를 생성하고 실행하는 구조라 개발자 입장에서 단순히 인터페이스를 하나 정의하는 작업만으로도 충분하다.
(기존의 Hibernate는 모든 코드를 직접 구현하고 트랜잭션 처리가 필요했으나, Spring Data JPA는 자동으로 생성되는 코드를 이용하므로 단순한 CRUD나 페이지 처리 등의 개발에 코드를 개발하지 않아도 된다.)
* '코드로 배우는 스프링 부트 웹 프로젝트'에 있는 예제를 진행하며 실제 Spring Data JPA를 어떤 방식으로 사용하게 되는지 알아보자.
1-1) 엔티티 클래스 작성
* entity패키지를 추가하고, Memo 클래스를 생성한다. (org.gorany.ex2.entity.Memo)

※ 키 생성 전략은 크게 다음과 같다. (strategy = GenerationType.xxxx)
- AUTO(default) : JPA 구현체(스프링 부투에서는 Hibernate)가 생성 방식을 결정
- IDENTITY : 사용하는 DB가 키 생성을 결정. MySQL, MariaDB의 경우 auto increment 방식을 이용
- SEQUENCE : DB의 시퀀스를 이용해 키를 생성. @SequenceGenerator와 같이 사용
- TABLE : 키 생성 전용 테이블을 생성해서 키 생성. @TableGenerator와 같이 사용
* @Column
- 만일 추가적인 컬럼(필드)이 필요한 경우에도 마찬가지로 어노테이션을 사용한다. @Column을 사용해 다양한 속성을 지정할 수 있다. 주로 [nullable, name, length, ... ] 등을 이용해 DB의 컬럼에 필요한 정보를 제공한다.
- 반대로 데이터베이스 테이블에는 컬럼으로 생성되지 않게 하려면 @Transient 어노테이션을 적용한다.

* @Builder를 사용하기 위해서는 @AllArgsConstructor와 @NoArgsConstructor를 함께 써줘야 컴파일 에러가 안난다.
1-2) Spring Data JPA를 위한 스프링 부트 설정
* 자동으로 필요한 테이블을 생성하거나, JPA를 이용할 때 발생하는 SQL 등을 확인하기 위해서는 추가적인 설정이 필요
* < 설정파일 > application.properties =>

* spring.jpa.hibernate.ddl-auto
프로젝트 실행 시 자동으로 DDL(create, alter, drop, ...)을 생성할 것인지 결정하는 설정.
설정 값은 create, updatem create-drop, validate가 있다.
* spring.jpa.properties.hibernate.format_sql
실제 JPA의 구현체인 Hibernate가 동작하며 발생하는 SQL을 포맷팅해서 출력한다. 실행되는 SQL의 가독성을 높여준다.
* spring.jpa.show-sql
JPA 처리 시에 발생하는 SQL을 보여줄 것인지 결정한다.
1-3) main() 실행 결과
Hibernate:
create table tbl_memo (
mno integer not null auto_increment,
text varchar(200) not null,
primary key (mno)
) engine=InnoDB
라고 로그에 출력되게 되며 테이블이 생성된다.
2-1) JpaRepository 인터페이스
* Spring Data JPA에는 여러 종류의 인터페이스 기능을 통해 JPA관련 작업을 별도의 코드 없이 처리할 수 있게 지원함.
* CRUD작업이나 페이징, 정렬 등의 처리도 인터페이스의 메서드를 호출하는 형태로 처리하는데 기능에 따라 상속 구조로 추가적인 기능을 제공한다.
Repository
↑
CrudRepository
↑
PagingAndSortRepository
↑
JpaRepository
* 일반적인 기능만을 사용하고자 할 때는 CrudRepository를 사용하는 것이 좋다.
* 모든 JPA관련 기능을 사용하고자 할 때는 JpaRepository를 이용하긴 하지만, 일반적으로 JpaRepository가 가장 무난함.
2-2) JpaRepository 사용하기
* JpaRepository는 인터페이스이고, Spring Data JPA는 이를 상속하는 것으로 모든 작업이 끝난다. 물론 실제 동작 시 스프링 내부에서 해당 인터페이스에 맞는 코드를 생성하는 방식을 이용한다.
public interface MemoRepository extends JpaRepository<Memo, Integer> {
}* repository패키지를 추가해 MemoRepository 인터페이스를 추가했고, JpaRepository 인터페이스를 상속했다.
* JpaRepository를 사용할 때는 엔티티의 타입 정보(Memo 클래스)와 @Id의 타입을 지정하게 된다. 이처럼 인터페이스 선언만으로 스프링의 빈(Bean)으로 등록된다. (내부적으로 인터페이스 타입에 맞는 객체를 생성해 빈으로 등록함)
2-3) CRUD
* MemoRepository를 이용해 SQL 없이 CRUD를 해보자. JpaRepository는 아래 메서드를 이용한다.
- INSERT : save(Entity Object)
- SELECT : findById(Key Type), getOne(Key Type)
- UPDATE : save(Entity Object)
- DELETE : deleteById(Key Type), delete(Key Type)
* insert와 update의 메서드로 save()를 사용하는데, JPA의 구현체가 메모리 상에서 객체를 비교하고 없다면 insert, 존재하면 update를 동작시킨다.
본 내용은 '코드로 배우는 스프링 부트 웹 프로젝트' 책의 내용을 인용하였다.
'Framework > Spring Boot' 카테고리의 다른 글
| [Spring Boot] Security 사용자 정보 출력 in Thymeleaf (0) | 2021.03.05 |
|---|---|
| [Spring Boot] JPA 관련 용어 (0) | 2021.02.20 |
| [Spring Boot] @MappedSuperClass (0) | 2021.01.14 |
| [Spring Boot] JPA 동적 검색 (QueryDsl) (1) | 2021.01.13 |
| [Spring Boot] Gradle의 Querydsl 설정 (1) | 2020.12.27 |


